Dla administratorów stron internetowych i specjalistów SEO, zrozumienie i efektywne wykorzystanie pliku robots.txt stanowi fundamentalny element optymalizacji serwisów pod kątem wyszukiwarek. Ten przewodnik stanowi cenne źródło wiedzy, oferując nie tylko wgląd w to, czym jest plik robots.txt, ale również przedstawiając jego znaczący wpływ na zarządzanie robotami indeksującymi witrynę. Artykuł ten zapewnia zarówno podstawowe, jak i zaawansowane informacje na temat tworzenia i zarządzania tym plikiem, ukazując jego rolę jako niezbędne narzędzie w kształtowaniu widoczności strony w Internecie.
Z tego artykułu dowiesz się:
- Jakie funkcje pełni plik robots.txt i dlaczego jest tak ważny dla każdej strony internetowej.
- Jak stworzyć i modyfikować plik robots.txt, aby lepiej kontrolować, które części Twojej strony są indeksowane przez wyszukiwarki.
- Jakie korzyści niesie za sobą odpowiednia konfiguracja pliku robots.txt, od lepszego zarządzania zasobami serwera po optymalizację procesu indeksowania.
- Jakie ograniczenia posiada plik robots.txt i jakie błędy należy unikać, aby nie zaszkodzić widoczności strony w wynikach wyszukiwania.
- Praktyczne wskazówki dotyczące testowania i weryfikacji skuteczności pliku robots.txt przy użyciu narzędzi takich jak Google Search Console.
Zarządzanie plikiem robots.txt to kluczowy element strategii SEO, który może znacząco wpłynąć na efektywność i widoczność Twojej strony w sieci. Zapraszamy do zagłębienia tematu i skorzystania z porad zawartych w tym artykule, aby maksymalnie wykorzystać potencjał tego narzędzia!
Czym jest plik robots.txt?
Plik robots.txt to standardowy dokument tekstowy, który komunikuje się z robotami przeszukującymi internet, takimi jak roboty Google. Umieszczony w głównym katalogu serwera, dyktuje, które sekcje witryny są dostępne do indeksowania. Jest to pierwszy element, z którym robot się zapoznaje, wchodząc na adres URL, co czyni go niezbędnym narzędziem dla administratorów witryn.
Oprócz tego robots.txt służy do zarządzania ruchem robotów indeksujących, co pozwala na lepsze kontrolowanie i optymalizację procesu przeszukiwania stron przez wyszukiwarki. Pomimo tego, że plik znajduje się w dostępnym miejscu, to zawarte w nim dyrektywy nie gwarantują pełnej ochrony przed indeksowaniem – sekcje zablokowane przez robots.txt nadal mogą być indeksowane, jeśli są odnośniki z innych części witryny Google lub z zewnętrznych źródeł. Dlatego tak ważne jest, aby uważnie zarządzać treścią pliku robots.txt, aby efektywnie wspomagać SEO i poprawiać widoczność strony w wynikach wyszukiwania.
Odpowiednie skonfigurowanie pliku robots.txt, może być odpowiedzią na pytanie: Dlaczego strona jest niewidoczna w Google?
Dlaczego warto podjąć się tworzenia pliku robots.txt – zalety robota na Twojej stronie
Plik robots.txt jest kluczowy dla efektywnej strategii SEO:
- Kontrola nad indeksowaniem – dzięki niemu możesz ograniczyć dostęp do nieistotnych lub prywatnych sekcji strony, skupiając roboty na najważniejszych treściach.
- Optymalizacja zasobów serwera – robot zapobiega nadmiernemu obciążeniu serwera przez częste żądania robotów, co jest istotne dla szybkości ładowania strony.
- Lepsze zarządzanie treścią – plik robots.txt umożliwia selektywne indeksowanie treści, co pomaga uniknąć problemów z duplikacją i poprawia ogólną widoczność strony w wynikach wyszukiwania.
Reguły pliku robots.txt – ograniczenia pliku robots.txt
Rozumienie reguł i ograniczeń pliku robots.txt jest kluczowe dla każdego, kto chce efektywnie zarządzać tym, jak roboty indeksują jego stronę internetową. Plik robots.txt jest potężnym narzędziem, ale jak każde narzędzie, ma swoje specyficzne ograniczenia i wymaga stosowania z rozwagą.
1. Reguły dotyczące instrukcji Disallow i Allow
Podstawową funkcją pliku robots.txt jest kierowanie ruchem robotów poprzez instrukcje Disallow i Allow. Disallow blokuje dostęp do określonych ścieżek na serwerze, co jest kluczowe, gdy chcemy ograniczyć indeksację nieistotnych lub prywatnych części strony. Na przykład, instrukcja Disallow: /tmp/ zapobiegnie indeksowaniu zawartości katalogu /tmp/.
Z kolei Allow, mimo że jest mniej powszechnie używane, służy do przywracania dostępu do konkretnych plików lub katalogów, które zostały zablokowane ogólniejszą instrukcją Disallow. To pozwala na bardziej zróżnicowane zarządzanie indeksowaniem treści, umożliwiając robotom dostęp do wybranych plików w zablokowanych ścieżkach.
2. Ograniczenia wynikające z ignorowania pliku
Ważnym ograniczeniem pliku robots.txt jest fakt, że nie wszystkie roboty przestrzegają zawartych w nim instrukcji. Niektóre roboty, szczególnie te związane z niechcianym oprogramowaniem lub próbujące zbierać dane w sposób nieuprawniony, mogą ignorować plik robots.txt. Dlatego nigdy nie powinien być on używany jako środek zabezpieczający do ochrony wrażliwych danych.
3. Plik robots.txt nie wpływa na linkowanie zewnętrzne
Innym ważnym ograniczeniem jest to, że plik robots.txt nie ma wpływu na linki prowadzące do strony z zewnątrz. Instrukcje zawarte w pliku robots.txt nie mogą zapobiec indeksowaniu strony, jeśli inne strony prowadzą do niej linki. W takim przypadku nawet jeśli plik zawiera instrukcję Disallow, treści mogą być nadal indeksowane przez wyszukiwarki, jeśli są dostępne przez linki z innych stron.
4. Ryzyko nadmiernego blokowania
Jednym z najczęstszych błędów w zarządzaniu plikiem robots.txt jest nadmierne blokowanie dostępu do treści, które mogłyby być korzystne dla pozycji strony w wyszukiwarkach. Nieprawidłowe użycie dyrektyw Disallow może prowadzić do wykluczenia ważnych stron z indeksu wyszukiwarki, co ostatecznie zaszkodzi widoczności strony internetowej.
5. Brak wymuszenia indeksowania
Plik robots.txt nie może wymusić indeksowania żadnej zawartości. Oznacza to, że nie możemy użyć pliku robots.txt, aby nakazać robotom, aby indeksowały określone części strony. Roboty wyszukiwarek samodzielnie decydują, które strony są indeksowane, na podstawie wielu czynników, w tym dostępności treści i linków zewnętrznych.
Zrozumienie tych ograniczeń jest niezbędne dla efektywnego wykorzystania pliku robots.txt w strategii SEO. Prawidłowo stosowany, może znacząco pomóc w optymalizacji strony dla wyszukiwarek, ale nieprawidłowe użycie może również przynieść szkody, blokując dostęp do wartościowych treści lub niewłaściwie zarządzając ruchem robotów.
Przykładowy plik robots.txt:
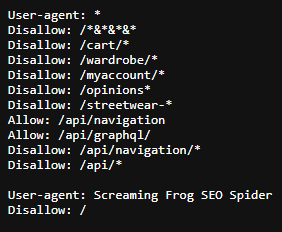
Jak utworzyć plik robots.txt? Kluczowe informacje do tworzenia pliku
Tworzenie pliku robots.txt jest niezwykle istotne dla każdej strony internetowej, która chce kontrolować sposób, w jaki jest przeszukiwana przez roboty wyszukiwarek, zwłaszcza wyszukiwarka Google. Aby prawidłowo stworzyć plik robots.txt, musisz zrozumieć, jakie elementy powinien zawierać i jakie zasady stosować, aby efektywnie zarządzać dostępem robotów do Twojej strony.
1. Rozpoczęcie pracy nad plikiem robots.txt
Zawartość pliku robots.txt musi być skonstruowana w taki sposób, aby spełniała specyficzne wymagania strony oraz wytyczne robotów. Plik txt powinien być umieszczony w głównym katalogu serwera, aby każdy robot odwiedzający stronę mógł go łatwo odnaleźć i przeczytać.
2. Zrozumienie i definiowanie User-agent
Pierwszym krokiem przy tworzeniu pliku robots.txt jest określenie, do których robotów mają odnosić się zawarte w nim instrukcje. Służy do tego dyrektywa User-agent. Przykładowo, jeśli chcesz zdefiniować reguły dla wszystkich robotów, użyjesz User-agent: *. Możesz również określić instrukcje dla konkretnego robota, np. Googlebot, wpisując User-agent: Googlebot.
3. Stosowanie dyrektyw Allow i Disallow
Kluczowymi elementami w pliku robots.txt są instrukcje Allow i Disallow, które kontrolują dostęp do różnych części Twojej strony. Disallow służy do wskazania robotom, które sekcje witryny mają być wyłączone z indeksacji. Na przykład, jeśli nie chcesz, aby robot indeksował katalog o nazwie „images”, wpiszesz:
Disallow: /images/Z kolei instrukcja
Allow jest używana, by zezwolić na indeksowanie konkretnych zawartości w miejscach, które generalnie zostały zablokowane. Przykładem może być zezwolenie na indeksowanie konkretnego obrazka w katalogu, który jest ogólnie blokowany:Disallow: /images/
Allow: /images/logo.png
4. Pełna zawartość pliku robots.txt
Pełna zawartość pliku robots.txt powinna być przemyślana i skonstruowana tak, by odzwierciedlała strategię SEO strony. Należy zwrócić uwagę, aby nie zablokować ważnych dla wyszukiwarki treści, co mogłoby negatywnie wpłynąć na widoczność strony. Każda instrukcja w pliku powinna być dokładnie przemyślana, z uwzględnieniem długoterminowych celów i potrzeb strony internetowej.
5. Testowanie pliku robots.txt
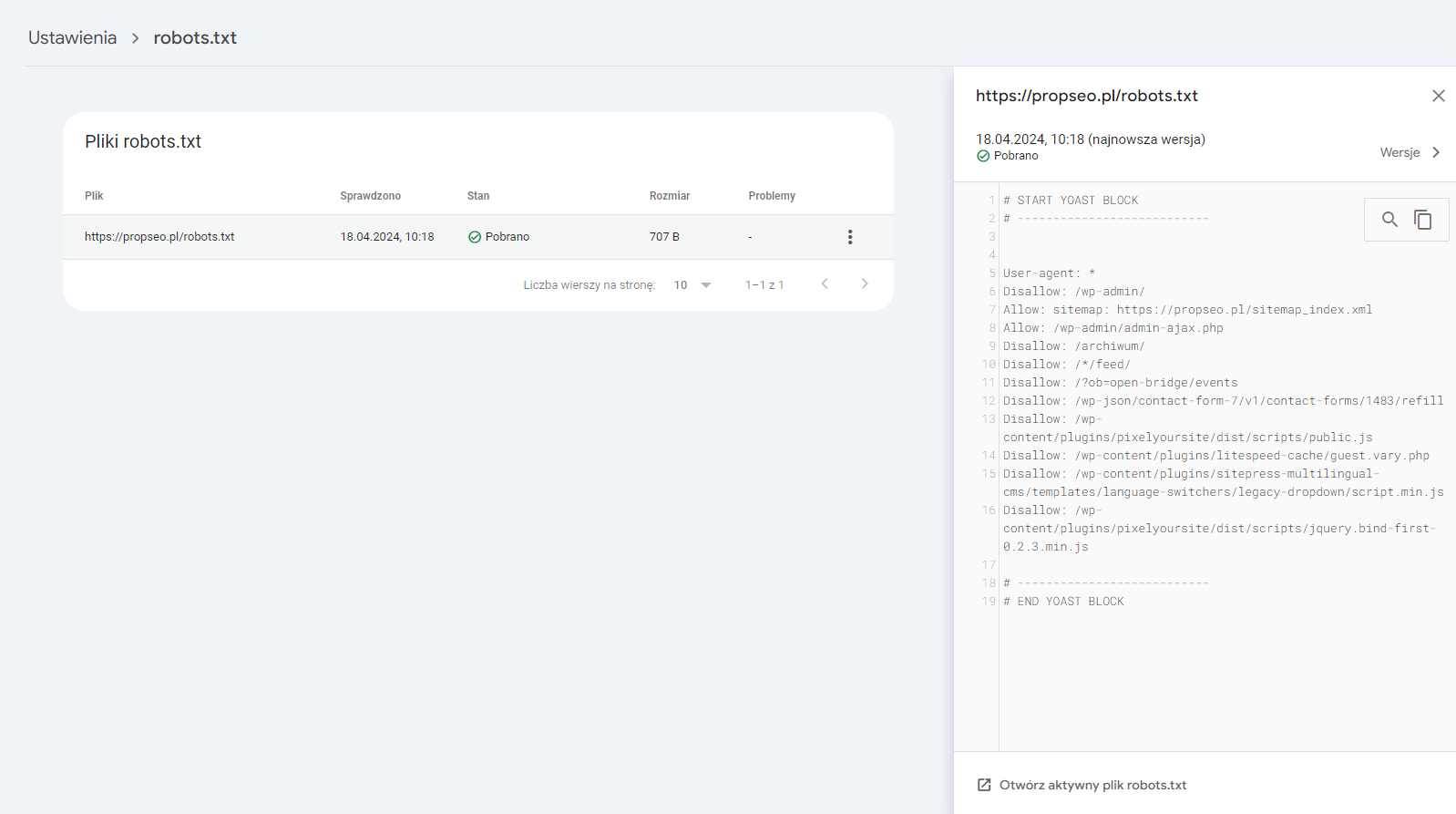
Po utworzeniu pliku robots.txt niezwykle ważne jest przetestowanie jego działania. Narzędzia takie jak Google Search Console umożliwiają sprawdzenie, czy plik działa zgodnie z oczekiwaniami, i czy odpowiednio komunikuje się z robotami wyszukiwarki Google. Testowanie pomoże wykryć ewentualne błędy i dostosować plik przed ostatecznym wdrożeniem.
Poniżej przykładowy panel pliku robots.txt w narzędziu Google Search Console oraz raport dotyczący pliku robots.txt
Robots.txt – podsumowanie
Plik robots.txt na stronie to kluczowe narzędzie, które służy do zarządzania ruchem robotów indeksujących. Jego odpowiednie skonfigurowanie jest niezbędne z punktu widzenia SEO, ponieważ pozwala na efektywną kontrolę nad tym, jakie treści są indeksowane. Warto zadbać o plik robots.txt, ponieważ znajduje się on na samym froncie interakcji z robotami wyszukiwarek – to pierwsze, z czym roboty się zapoznają, wchodząc na adres URL. Dzięki temu plikowi można skutecznie eliminować niepożądane URL z wyników wyszukiwania Google, co pomaga w optymalizacji dostępności i widoczności strony w internecie.
Podsumowanie kluczowych informacji o pliku robots.txt:
- Znaczenie pliku robots.txt – plik robots.txt jest jednym z pierwszych elementów, z którym roboty się zapoznają, wchodząc na adres URL Twojej witryny. Umożliwia kontrolę nad tym, które sekcje domeny mają być skanowane i które mogą być zindeksowane przez wyszukiwarkę Google.
- Zarządzanie dostępem – dzięki regułom w pliku robots.txt możesz precyzyjnie określić, które części Twojej witryny mają być dostępne dla robotów. Plik ten pozwala na efektywną kontrolę nad procesem skanowania i indeksowania treści.
- Optymalizacja SEO – korzystając z pliku robots.txt, wpływasz bezpośrednio na wyniki wyszukiwania Google. Plik ten pozwala na wykluczenie niepożądanych stron z indeksu, co pozwala skupić roboty na najważniejszych treściach, zwiększając ich widoczność.
- Integracja z Sitemap – plik robots.txt może zawierać odniesienia do pliku sitemap, co ułatwia robotom odkrywanie i indeksowanie wszystkich możliwych do odczytania przez Google części witryny, co jest szczególnie istotne dla nowych lub dużych stron internetowych.
- Komunikacja z robotami – robots.txt przekazuje robotom wyraźne instrukcje co do sposobu traktowania stron w Twojej domenie. Dzięki temu możesz zapobiegać nadmiernemu obciążeniu serwera i zabezpieczyć prywatne sekcje przed indeksowaniem.
- Testowanie i modyfikacje – za pomocą pliku robots.txt i narzędzi takich jak Google Search Console możesz testować i dostosowywać ustawienia w celu optymalizacji widoczności w wynikach wyszukiwania. Regularne sprawdzanie i aktualizacja tego pliku jest kluczowe dla utrzymania skuteczności SEO.
Inspiracje:
